
路径分析定义
 路径分析是一种统计技术,用于检查和检验一组变量之间的因果关系。因果关系在特征上是方向性的,并且当一个变量(例如练习量)导致另一个变量(例如身体适应性)发生变化时,就会发生。研究人员根据研究人员感兴趣的理论模型指定了这些关系。通常以路径图的形式将所得路径模型和路径分析的结果一起呈现。
路径分析是一种统计技术,用于检查和检验一组变量之间的因果关系。因果关系在特征上是方向性的,并且当一个变量(例如练习量)导致另一个变量(例如身体适应性)发生变化时,就会发生。研究人员根据研究人员感兴趣的理论模型指定了这些关系。通常以路径图的形式将所得路径模型和路径分析的结果一起呈现。
尽管路径分析对变量如何相关的因果推断,但相关数据实际上用于进行路径分析。在许多情况下,分析的结果提供了有关研究人员假设模型的合理性的信息。但是,即使该信息不可用,路径分析也提供了模型中变量之间因果效应和其他关联的相对强度的估计。这些估计值在研究人员的指定模型实际上表示变量与感兴趣的人群中真正相关的程度更为有用。
路径分析中的变量
路径分析是一种更通用的统计分析类型的成员,称为结构方程建模。将其与一般结构方程模型分开的路径分析的特征是,路径分析仅限于测量或观察到的变量,而不是潜在。这意味着路径分析中的每个变量都以直接的方式组成一组数字。例如,如果每个人的外向性水平由该人的单个数字表示,则可以将额外转换视为一个测量或观察到的变量,也许是在外向性调查表中的得分。因此,整个外向性的变量将包含样本中每个人的一个数字。通过某些统计技术,通过同时使用几种不同的度量来表示每个人的外向性水平,可以将外向性视为结构方程模型中的潜在变量。但是根据定义,路径分析不使用潜在变量。
型号规范
研究人员必须通过指定感兴趣的变量相互关联的方式来开始路径分析。这是基于理论和推理来完成的,研究人员必须周到地指定模型。该过程的一个关键方面是确定哪些特定变量因果关系影响其他特定变量。锻炼使身体健康的模型与良好健康导致运动的模型具有截然不同的含义。但是在许多情况下,这种替代路径分析的数字结果几乎没有或什么都没有透露哪种模型更接近事实。因此,无法替代对路径模型的形式具有声音原理的研究人员。
路径图
路径图是路径模型的视觉显示和路径分析的结果。在路径图中,测得的变量通常表示为正方形或矩形。从一个变量到另一个变量(例如,从焦虑到寻求注意力;请参见图1中所示的标准化路径图)的单头箭头(也称为路径或直接效应)意味着焦虑值的变化是被认为会导致注意力的价值发生变化(反之亦然)。研究人员不必提前指定第一个变量的增加是否会导致第二个变量的增加或减少。数学算法将估计效果的幅度及其阳性或负效率。
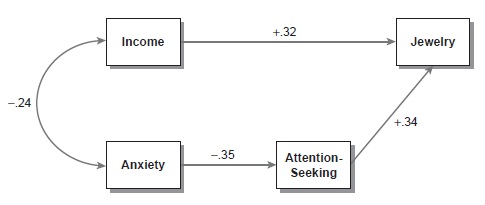
图1基于完全虚构数据的示例路径分析
双头箭头(有时被称为标准化路径图中的相关性,或在非标准图中的协方差)是指假定两个连接的变量相互关联(再次是正面或负面的),但没有特定的假设的原因(与收入和焦虑一样)。这种类型的关系有时被称为未分析的关联,因为路径模型无法解决为什么这两个变量关联的原因。他们只是被允许自由交往。
数据
研究人员指定了路径模型后,就必须拥有可用的数据来执行分析。图1的完全虚构示例中的变量是收入(每年收入为美元),焦虑症(心理焦虑问卷的分数),寻求注意力(也是问卷分数)和珠宝的印象(例如,每种评分)person’s jewelry done by a trained coder). What is required is a sample of data in which each of these variables has been measured for each case in the sample. So the researcher would need a sufficiently large group of people for whom values of each of these four variables are available.
路径分析软件的主要输入是指示每对变量之间关联的强度和符号(正或负)的数字。每个唯一的变量都有一个这样的数字。根据分析的形式,这些关联可以称为相关或协方差。无论如何,此输入信息的一个定义特征是,这些数据本身实际上没有任何因果关系。它们只是为模型中每对变量的关联强度索引,无论是正还是负数。
模型拟合
路径分析中使用的变量数量限制了路径模型的复杂性。在大多数情况下,如果模型具有与独特的变量对一样多的路径和相关性,则尽可能复杂。诸如此类的模型被称为公正识别模型。但是,这并不意味着更复杂的模型必然是更可取的。更复杂的模型不那么简单。
在图1中,有四个变量,因此有4(4-1)/2 = 6个唯一的变量对。由于图1中的路径和相关性少于独特的变量对,因此该模型不仅被识别。诸如此类的模型被称为过度识别模型。过度识别模型的理想属性是路径分析通常可以提供有关模型拟合的信息。此信息的最基本部分称为卡方统计量。在与此统计量相关的概率值相对较低的程度上,研究人员指定了一个路径模型,该路径模型在样本数据中的人群中是正确的。换句话说,研究人员面临的证据表明,指定的模型是对人口实际发生的事情的代表。
除了卡方统计量之外,还可以使用模型适用性索引。这部分是因为许多研究人员认为卡方统计量通常是对结构方程模型的测试。这些替代拟合指数的使用与拒绝研究人员指定模型的可能性较低有关。从卡方统计数据中拟合信息的程度应平衡其他指数的更宽容标准是一个有争议的问题。不管研究人员如何选择强调每种拟合信息,都必须知道它们仅适用于过度识别模型。此外,重要的是要了解,即使模型差不佳意味着研究人员指定的模型可能不准确,但良好的合适性绝不能保证模型的正确性。例如,研究人员本来可以省略重要变量或误指出了一个或多个因果箭头的方向,但仍然有可能拟合。
路径系数
所有路径分析均提供连接观察到的变量的路径和相关值的估计。尽管研究人员指定了特定路径和相关性的存在或不存在,但这些系数的特定值完全通过作用于样本数据的路径分析的数学算法来计算。它们是数学上最好的可用估计值,即如果可以分析整个人群,则该系数将是什么。这些值通常显示在适当路径旁边的图中(见图1)。
标准化(与非标准化)系数通常在路径图中显示。标准化系数的使用尝试尝试比较路径和相关性的相对强度,即使涉及的变量可能具有非常不同的测量范围。这些标准化系数的价值范围从-1.00到+1.00。更大的绝对值表示关系更强,符号(+或 - )表示因果变量的增加是导致变量的预测增加(+)还是减少( - ),还是相关性是正值还是负相关。
更改箭头的方向,消除它,用相关替换或更改模型中包含的变量可能会导致该路径强度的不同值,并且可以以不可预测的方式影响模型中的其他路径。相关的是,在具有三个或三个变量的路径分析中,从变量x到可变y的路径可能具有非常不同的强度甚至不同的符号(+ vers-),而与查看x和x之间的简单关联可能期望的那样。y一个人。由于这些原因,路径分析可能是一项非常有用的技术。但是,无论是信息的还是误导性的,都取决于研究人员模型的健全性和样本数据的代表性。
在图1中,收入和焦虑的相关性为-.24,这意味着较高的收入与这些样本数据中较低的焦虑水平有关。从收入到珠宝的道路的价值+.32意味着预计收入的增加将直接引起人们珠宝的印象。重要的是,该模型断言,可以认为收入与人们的珠宝的印象相关,两种不同的方式。尽管收入对珠宝产生了直接影响(+.32),但由于焦虑的相关性,它也与珠宝相关,因为焦虑会引起注意力的注意力,这又导致珠宝的变化。该路径分析将收入和珠宝之间的原始样本关联分解为基于研究人员的理论模型和样本数据的这两个概念上不同的部分。基于理论的分解推论是路径分析的本质。
还请注意,焦虑与该模型中的珠宝无直接相关。因此,该模型断言,这些变量在人群中之间的关联可以通过收入和注意力寻求全部解释。在某种程度上,这种理论断言是错误的,模型拟合的指标往往会更糟。
参考:
- Cohen,J.,Cohen,P.,West,S.G。,&Aiken,L.S。(2003)。为行为科学应用多元回归/相关分析。新泽西州马瓦(Mahwah):埃尔鲍姆(Erlbaum)。
- Keith,T。Z.(2006)。多元回归及以后:多元回归,验证性因素分析和结构方程建模的概念介绍。波士顿:Allyn&Bacon。
- Kline,R。B.(1998)。结构方程建模的原理和实践。纽约:吉尔福德出版社。
- Wonnacott,T。H.和Wonnacott,R。J(1981)。回归:统计学的第二课程。纽约:威利。